目录
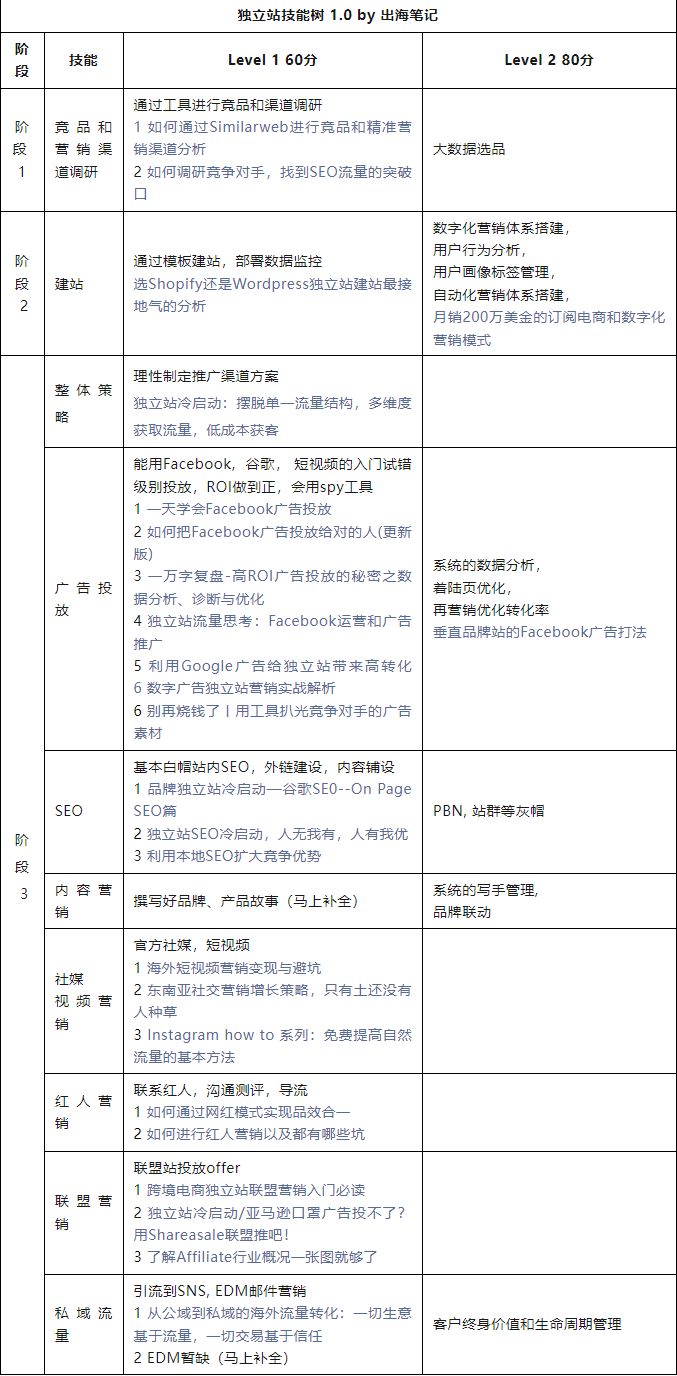
整体执行流程
Map端执行流程
Reduce端执行流程
Shuffle执行流程
整体执行流程
八部曲
读取数据--> 定义map --> 分区 --> 排序 --> 规约 --> 分组 --> 定义reduce --> 输出数据
首先将文件进行切片(block)处理,每一个block由一个MapTask处理
读取数据
将切片中每一行内容解析为键值对 <key,value>
定义map
每解析出一个键值对,就调用一次Mapper类中的map方法
分区
根据这些输出的键值对进行分区,分区的数量为reduce任务运行的数量(默认1个)
排序
对输出的键值对进行排序
规约
对这些键值对进行局部聚合处理,combiner处理,键值相等的键值对会调用一次reduce方法(默认没有本阶段 )
分组合并
Reduce任务会主动从Mapper任务中复制它输出的键值对到Reduce本地数据中,对所有的数据合并 然后再对这个大数据进行排序
定义reduce
对排序后的键值对调用reduce方法(键相等的键值对调用一次reduce方法)
输出数据
将输出的键值对写入到hdfs文件中
Map端执行流程

- 第一阶段是把输入目录下文件按照一定的标准逐个进行逻辑切片,形成切片规划。默认情况下,Split size = Block size。每一个切片由一个MapTask处理。(getSplits)
- 第二阶段是对切片中的数据按照一定的规则解析成<key,value>对。默认规则是把每一行文本内容解析成键值对。key是每一行的起始位置(单位是字节),value是本行的文本内容。(TextInputFormat)
- 第三阶段是调用Mapper类中的map方法。上阶段中每解析出来的一个<k,v>,调用一次map方法。每次调用map方法会输出零个或多个键值对。
- 第四阶段是按照一定的规则对第三阶段输出的键值对进行分区。默认是只有一个区。分区的数量就是Reducer任务运行的数量。默认只有一个Reducer任务。
- 第五阶段是对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值对<2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果是<1,3>、<2,1>、<2,2>。如果有第六阶段,那么进入第六阶段;如果没有,直接输出到文件中。
- 第六阶段是对数据进行局部聚合处理,也就是combiner处理。键相等的键值对会调用一次reduce方法。经过这一阶段,数据量会减少。本阶段默认是没有的。
Reduce端执行流程

- 第一阶段是Reducer任务会主动从Mapper任务复制其输出的键值对。Mapper任务可能会有很多,因此Reducer会复制多个Mapper的输出。
- 第二阶段是把复制到Reducer本地数据,全部进行合并,即把分散的数据合并成一个大的数据。再对合并后的数据排序。
- 第三阶段是对排序后的键值对调用reduce方法。键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对。最后把这些输出的键值对写入到HDFS文件中。
Shuffle执行流程

map阶段处理的数据如何传递给reduce阶段,是MapReduce框架中最关键的一个流程,这个流程就叫shuffle。
shuffle: 洗牌、发牌——(核心机制:数据分区,排序,合并)。
1).Collect阶段:将MapTask的结果输出到默认大小为100M的环形缓冲区,保存的是key/value,Partition分区信息等。
2).Spill阶段:当内存中的数据量达到一定的阀值的时候,就会将数据写入本地磁盘,在将数据写入磁盘之前需要对数据进行一次排序的操作,如果配置了combiner,还会将有相同分区号和key的数据进行排序。
3).Merge阶段:把所有溢出的临时文件进行一次合并操作,以确保一个MapTask最终只产生一个中间数据文件。
4).Copy阶段: ReduceTask启动Fetcher线程到已经完成MapTask的节点上复制一份属于自己的数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阀值的时候,就会将数据写到磁盘之上。
5).Merge阶段:在ReduceTask远程复制数据的同时,会在后台开启两个线程对内存到本地的数据文件进行合并操作。
6).Sort阶段:在对数据进行合并的同时,会进行排序操作,由于MapTask阶段已经对数据进行了局部的排序,ReduceTask只需保证Copy的数据的最终整体有效性即可。
Shuffle中的缓冲区大小会影响到mapreduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快








![[数据集][目标检测]智慧交通铁轨裂缝检测数据集VOC+YOLO格式4类别](https://i-blog.csdnimg.cn/direct/98f119a9b6384f9d93cda4f2906f041d.png)